Updated : Inside Prompt Caching: KV Reuse, Prefixes, and 90% Cost Reductions
The team that cut their API bill by 90% without changing a single line of model code
A startup was running a customer support AI. Their system prompt was 2,400 tokens — detailed instructions, persona definition, example conversations, product context. Every user message triggered a new API call. Every API call paid for those 2,400 tokens again. All day, every day, for every user, for every message.
Their monthly API bill was $8,200.
A backend engineer noticed something in the Anthropic API documentation: a parameter called
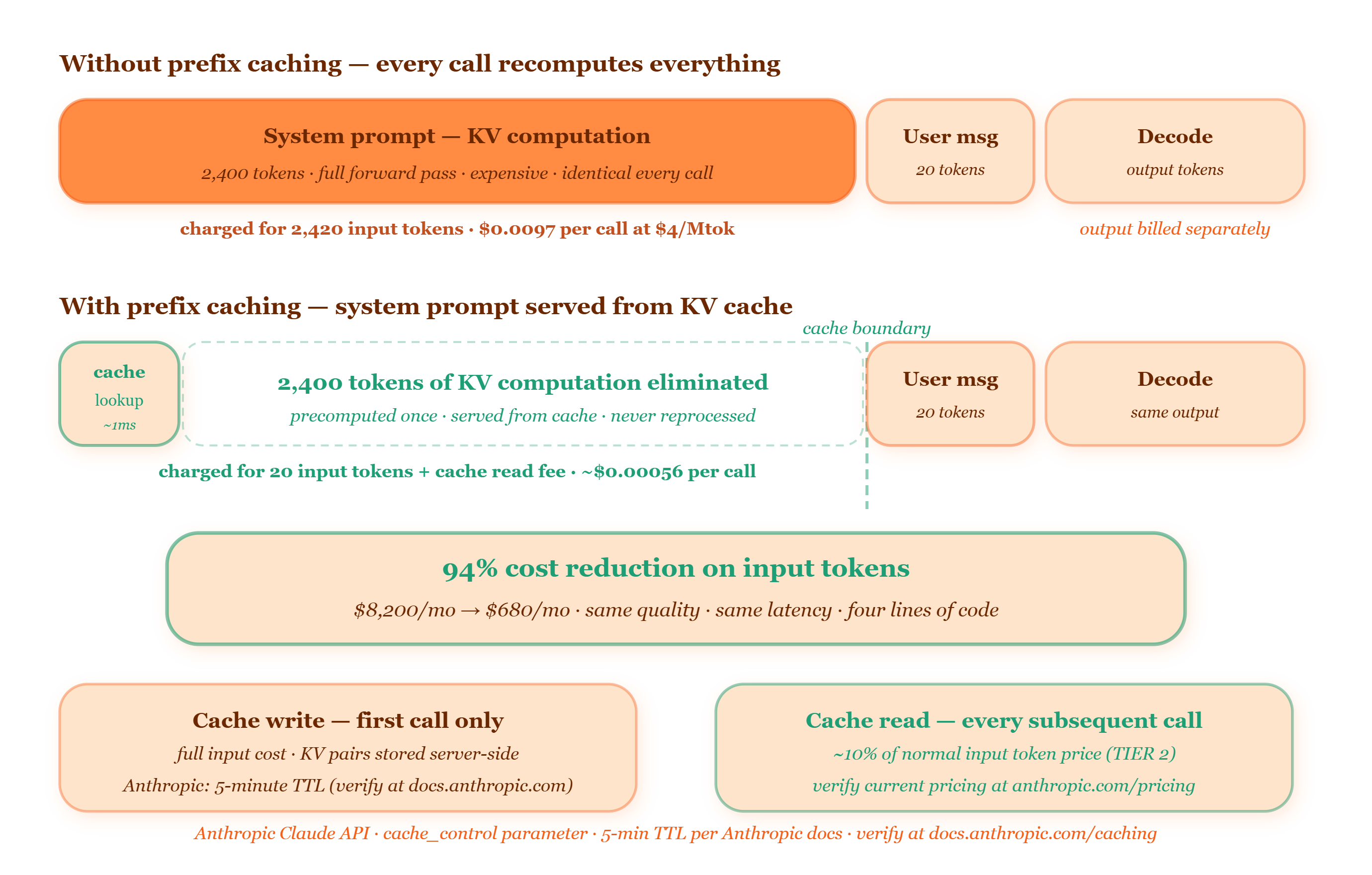
cache_control. She added four lines of code. The system prompt was now marked as cacheable. On the next deploy, 94% of their API calls hit the cache on the prompt prefix instead of re-processing it from scratch.Their next monthly bill was $680.
No model change. No architecture change. No quality change. No latency change — if anything, cached calls were faster. The system prompt had been re-processed 847,000 times that month. After the change: zero times.
This is prompt caching — specifically, Anthropic’s implementation called prefix caching. And the reason it works is deeply connected to how transformer attention actually processes text.
Why re-reading the same text 847,000 times is not free
When an LLM processes a prompt, it doesn’t just read it — it computes. For every token in the input, across every attention layer, the model generates a key vector and a value vector. These KV pairs — which we covered in Issue #05 on PagedAttention — are what the model uses when it attends to prior context during generation.
For a 2,400-token system prompt on a large model, generating those KV pairs means running the full transformer forward pass over 2,400 tokens. That computation costs time and money. It happens before the first output token appears. It is, in fact, the dominant cost for short user messages with long system prompts.
Now consider: the system prompt doesn’t change between calls. The instructions are the same. The persona is the same. The product context is the same. The KV pairs for those 2,400 tokens are identical every single time. But without caching, you recompute them identically from scratch on every single API call.
Prefix caching stores those KV pairs on the server after the first computation. Every subsequent call that starts with the same prefix skips the computation entirely and loads the precomputed KV pairs directly. The model picks up from where the cached prefix ends and processes only the new user message — which might be 20 tokens.
Think of it like a chef who makes the same soup base every morning. Without caching: the chef makes the base fresh for every bowl. With caching: the chef makes the base once, keeps it on the stove all day, and adds the customer’s specific ingredients to each portion. Same soup. Fraction of the work.
Here’s the key thing: prefix caching reduces the cost of repeated context not by making computation faster but by eliminating the repeated computation entirely — and the savings scale directly with how long your static prefix is relative to each new user message.
What caching does to the KV computation graph