Ring-AllReduce Explained: The Distributed Training Bottleneck Nobody Monitors
The training run that crashed at 94% because one GPU was slow
A research team at an AI lab was running a distributed training job across 128 GPUs. The job had been running for eleven days. At 94% completion — roughly 18 hours from finishing — it stopped making progress. The loss curve had flatlined. Every metric looked normal. GPU utilisation was high across the board. The job was consuming power and producing nothing useful.
The culprit: one GPU out of 128 was running 12% slower than the rest due to a thermal throttling event. In synchronous distributed training, the cluster can only move as fast as the slowest participant. The other 127 GPUs finished each step and waited. And waited. And waited for that one slow GPU to catch up.
The team had no alerting on per-GPU step time variance. They had overall job progress, which looked healthy until it didn’t. By the time they identified the straggler, they had wasted roughly 127 GPU-days of compute — because 127 GPUs had been idle for 18 hours.
This is the straggler problem. It’s the defining challenge of synchronous distributed training at scale. And Ring-AllReduce is the algorithm that everyone uses for gradient synchronisation — which means understanding Ring-AllReduce means understanding exactly why the straggler problem is so expensive.
Getting 128 GPUs to agree on a single number — without asking anyone to be the boss
When you train a neural network across multiple GPUs, each GPU processes a different slice of the training data in each step. Each GPU computes its own gradients — the update directions for each weight. But the model update has to use the average gradient across all GPUs, not just one GPU’s gradients. Otherwise different GPUs would move their copy of the model in different directions and the copies would diverge.
The naive solution is to have a central server collect all gradients, average them, and send the result back to everyone. This is called a Parameter Server. It works. It’s also a bottleneck. The parameter server receives gradients from all 128 GPUs simultaneously and sends updates back to all 128 GPUs simultaneously. Every byte of gradient data flows through one machine. At 128 GPUs with large models, this single machine becomes the constraint on your training speed.
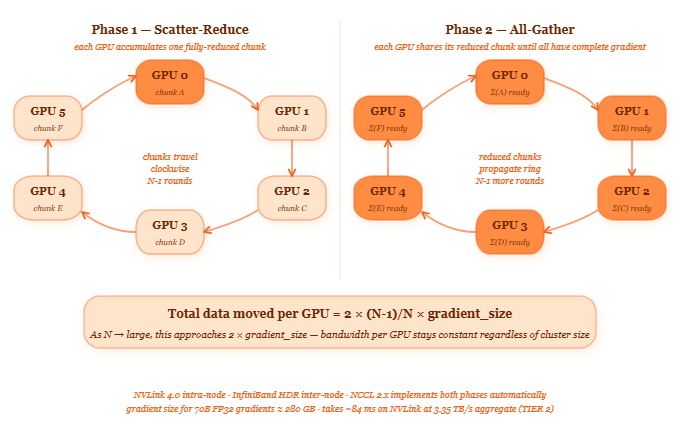
Ring-AllReduce eliminates the central server entirely. It arranges the GPUs in a logical ring — GPU 0 connects to GPU 1, GPU 1 to GPU 2, all the way around to GPU 127 connecting back to GPU 0. No GPU talks to all others. Every GPU talks only to its two neighbours.
Think of a bucket brigade at a fire. Twenty people stand in a line between the water source and the fire. Each person passes a bucket to the next person. Every person is working simultaneously. No one person is the bottleneck. The speed of the brigade is determined by how fast each person can pass a bucket — not by any single person’s workload.
Here’s the key thing: Ring-AllReduce moves gradient data through the network at a rate limited only by the bandwidth of each individual GPU-to-GPU link — not by any central node — and every GPU participates in forwarding simultaneously, so the total time to synchronise gradients is nearly independent of the number of GPUs.
The ring, the chunk, and the two-phase flow