

NVFP4 kernels: what register pressure actually means
AI SYSTEM DESIGN · Issue #03 · May 2026
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━. AI SYSTEM DESIGN · Issue #03 · May 2026 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
The team that halved their inference cost without buying anything new
A serving team at a computer vision company was running image captioning at scale. Their model was a 13B parameter vision-language model. Their GPU cost was the single largest line item on the infrastructure budget.
Someone on the team tried switching from BF16 precision to NVFP4 — a new 4-bit floating-point format that shipped with Blackwell-generation NVIDIA hardware. Same model. Same cluster. Same traffic.
Their token throughput doubled. Their memory footprint dropped by 60%. Their cost per image caption fell by roughly half.
What confused them: they expected quality to collapse. It didn’t. Perplexity on their eval set moved by less than 0.3%. The model still passed their human evaluation threshold.
They hadn’t changed the model. They hadn’t changed the architecture. They’d changed the number format the GPU used to store and compute weights. That’s it. And the reason it worked — without destroying accuracy — is the thing most engineers never fully understand about how modern GPUs represent numbers.
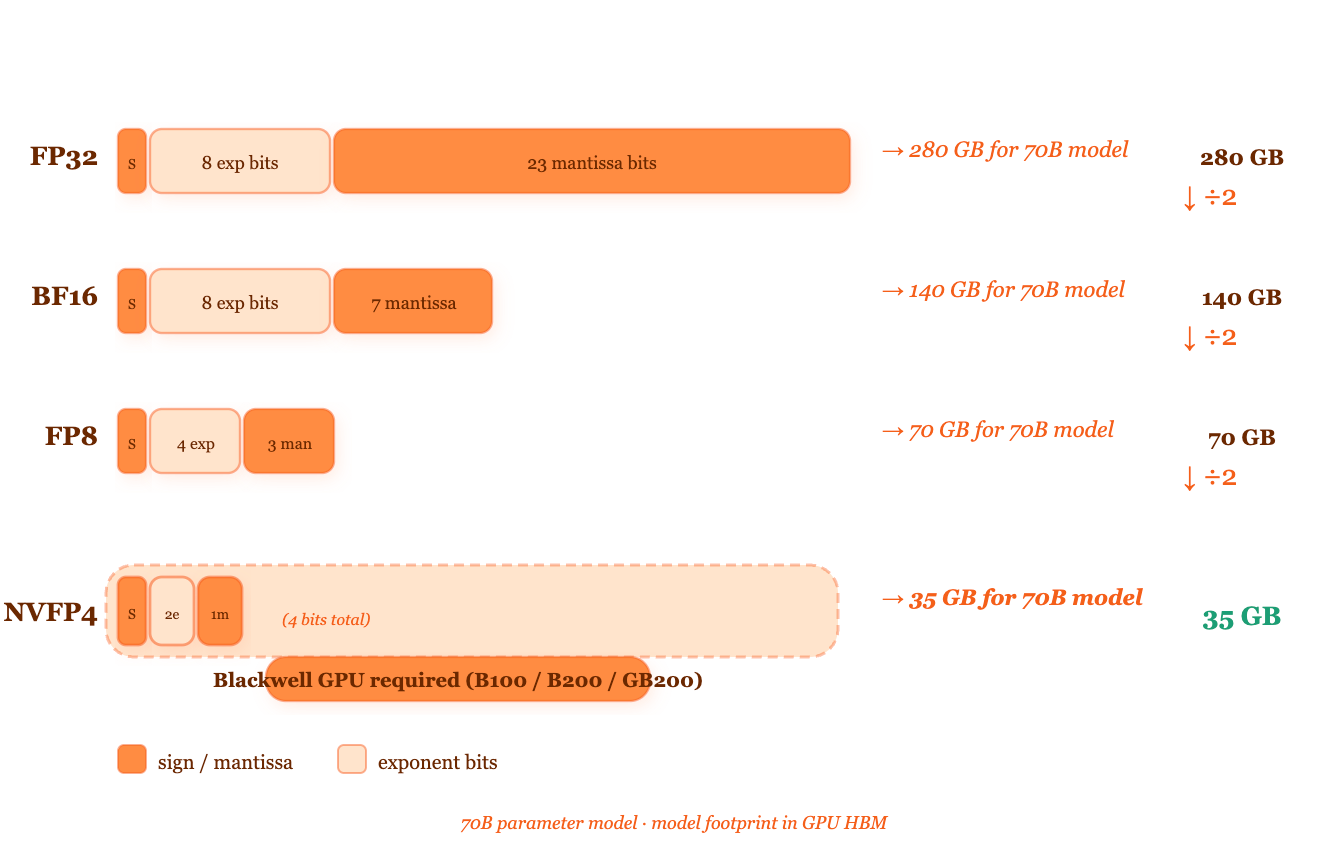
Numbers take up space. NVFP4 takes up less of it — without losing what matters.
When a GPU stores a number, it doesn’t store the number the way your calculator does. It stores it as a pattern of bits using a format called floating point.
The most common format is FP32 — 32 bits per number. That gives you an enormous range (about 10^38) and very fine precision. Then came FP16 — 16 bits, still enough precision for most AI work, half the memory. Then BF16 — also 16 bits, but with a wider range and slightly coarser precision, which works better for training. Then FP8 — 8 bits, which NVIDIA’s H100 SXM5 introduced for inference and training.
NVFP4 is 4 bits per number. It’s specific to NVIDIA Blackwell-generation GPUs — the B100, B200, and GB200 NVL72 — and it was designed from the start for transformer inference.
But here’s where most people’s mental model breaks down. They think: “4 bits means less precision, which means wrong answers.” That’s not quite right. The question isn’t how many bits you use in total — it’s which bits matter for your specific computation.
A transformer weight matrix has a statistical structure. Most values cluster near zero. A small number are large. The distribution isn’t uniform. FP4 formats are designed to match that distribution — they give more representational density to small values and less to large ones. The precision where your model actually concentrates its weights is preserved. The precision in ranges your weights never actually occupy is sacrificed.
Think of a map. A city map has very fine detail in the urban centre — every street, every building. The suburbs get coarser detail. The countryside beyond is just a rough outline. The total paper is the same. The detail is placed where the map is most used. NVFP4 does the same thing with numeric precision.
Here’s the key thing: NVFP4 doesn’t reduce the quality of the numbers your model uses — it reallocates precision to where your model’s weights actually live
What NVFP4 storage looks like compared to the formats before it
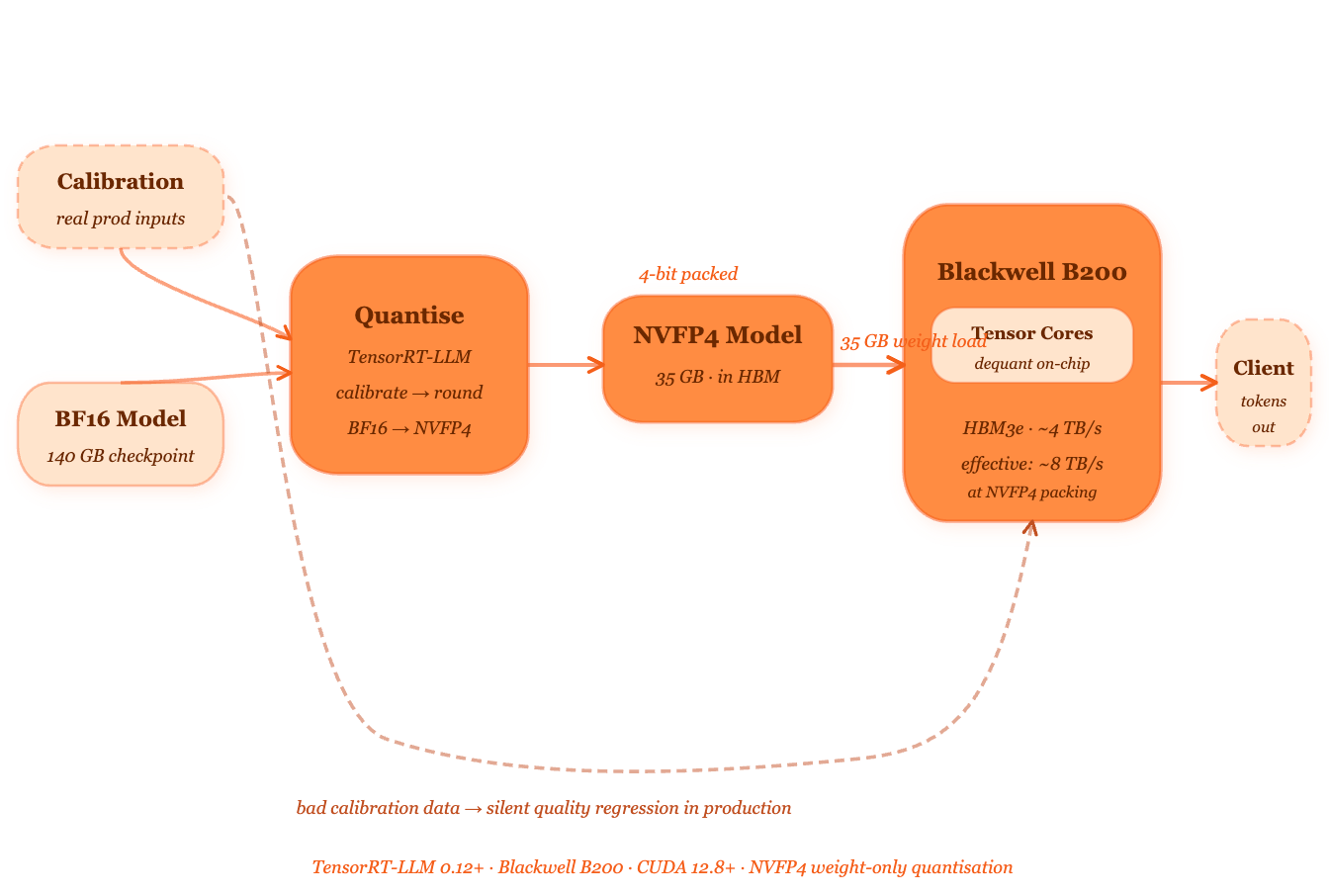
What actually happens inside a Blackwell chip when it runs NVFP4
Here’s the mechanism, step by step.
NVFP4 weights are stored in HBM at 4 bits per number. When the GPU loads a weight matrix for a matrix multiplication, it pulls those 4-bit values from HBM into the chip. Because each weight is half the size of an FP8 weight and a quarter the size of a BF16 weight, twice as many weights fit in each HBM transfer. The same 2 TB/s of bandwidth delivers twice the effective weight throughput. The memory wall from Issue #01 gets shorter — not because the wall moved, but because you packed more useful information into each trip through it.
But the GPU can’t do arithmetic directly on 4-bit numbers for most operations. So Blackwell’s Tensor Cores dequantise on the fly — they convert NVFP4 weights to a higher-precision format during the multiply-accumulate operation. This conversion happens in hardware, inside the chip, at essentially zero additional cost. The computation itself runs in higher precision. Only the storage and the memory transfer run at 4 bits.
This is called weight-only quantisation at storage time. The weights are stored small. The arithmetic runs bigger. The accuracy loss comes only from the precision you lost during the original quantisation step — not from the arithmetic itself.
# Using NVIDIA TensorRT-LLM 0.12+ for NVFP4 inference on Blackwell hardware
# Verify API at nvidia.github.io/TensorRT-LLM (evolves frequently)
# Requires: Blackwell GPU (B100/B200/GB200), CUDA 12.8+
from tensorrt_llm import LLM, SamplingParams
from tensorrt_llm.quantization import QuantConfig, QuantAlgo
quant_config = QuantConfig(
quant_algo=QuantAlgo.NVFP4, # ← this single line enables NVFP4
kv_cache_quant_algo=None # KV cache stays in FP8 — safer for accuracy
)
llm = LLM(
model="meta-llama/Meta-Llama-3.1-70B-Instruct",
quant_config=quant_config,
tensor_parallel_size=4 # still recommended for 70B even at NVFP4
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=256)
outputs = llm.generate(["Explain the memory wall in AI inference."], sampling_params)
print(outputs[0].outputs[0].text)Most people assume quantisation is a single compression step you apply once. In practice it involves three distinct operations: calibration, quantisation, and runtime dequantisation. Calibration means running a sample of real inputs through the model to measure the statistical distribution of weight values — this is how the quantiser decides which numeric ranges to prioritise. Quantisation is when you actually convert the weights from BF16 to NVFP4, rounding values to the nearest representable 4-bit number. Dequantisation is what the GPU does at inference time, converting those stored 4-bit weights back to a workable precision for the actual computation.
Skip calibration or do it on a bad sample and quality suffers badly. The calibration dataset should reflect your real production inputs — not just random text pulled from the internet.
Where NVFP4 fits in a Blackwell inference cluster
The two things that make or break NVFP4 in production
Two upstream decisions determine whether NVFP4 helps or hurts you.
The first is hardware generation. NVFP4 is exclusive to NVIDIA Blackwell GPUs — the B100, B200, and GB200 NVL72. It is not available on Hopper (H100 SXM5, H100 PCIe) or Ampere (A100). Those GPUs support FP8 at minimum and BF16 as the standard. If you’re running Hopper hardware, NVFP4 is not an option — full stop. Check nvidia-smi --query-gpu=name --format=csv before planning anything around this format.
The second is calibration data quality. Quantisation accuracy depends entirely on how well your calibration dataset represents your real production inputs. A calibration set that looks nothing like what your users send will produce a model that scores well on generic benchmarks and fails silently on your actual traffic. The calibration step needs real anonymised production queries — not a generic dataset pulled from a research benchmark.
When both are right, two downstream effects compound each other. First, you move more weight data per unit of HBM bandwidth — on a B200 with HBM3e at roughly 4 TB/s, loading NVFP4 weights delivers the effective weight throughput of an 8 TB/s link, because each transfer carries twice as many weights. Second, you fit larger models on fewer GPUs. A 70B model that previously needed 4× H100 SXM5 in TP=4 at BF16 fits on 2× B200 at NVFP4 — same model capability, half the hardware.
When calibration is wrong, the failure is silent. The model doesn’t crash. It doesn’t throw an error. It quietly produces lower-quality outputs on the specific input types your calibration set missed. You won’t notice it until users complain or your eval metrics slip. Run a quality regression eval on held-out production samples before any NVFP4 deployment goes live.
Which precision format to reach for, and when
When you’re choosing a numeric format for inference, the decision tree is actually short. Most of it hinges on your hardware generation and how much accuracy risk you’re willing to accept.
START: Do you have Blackwell GPUs (B100, B200, or GB200)?
│ (check via nvidia-smi — Blackwell shows as "Compute Capability 10.x")
├── YES → Is quality regression under 1% acceptable for your use case?
│ │ (measure on held-out production samples, not benchmark datasets)
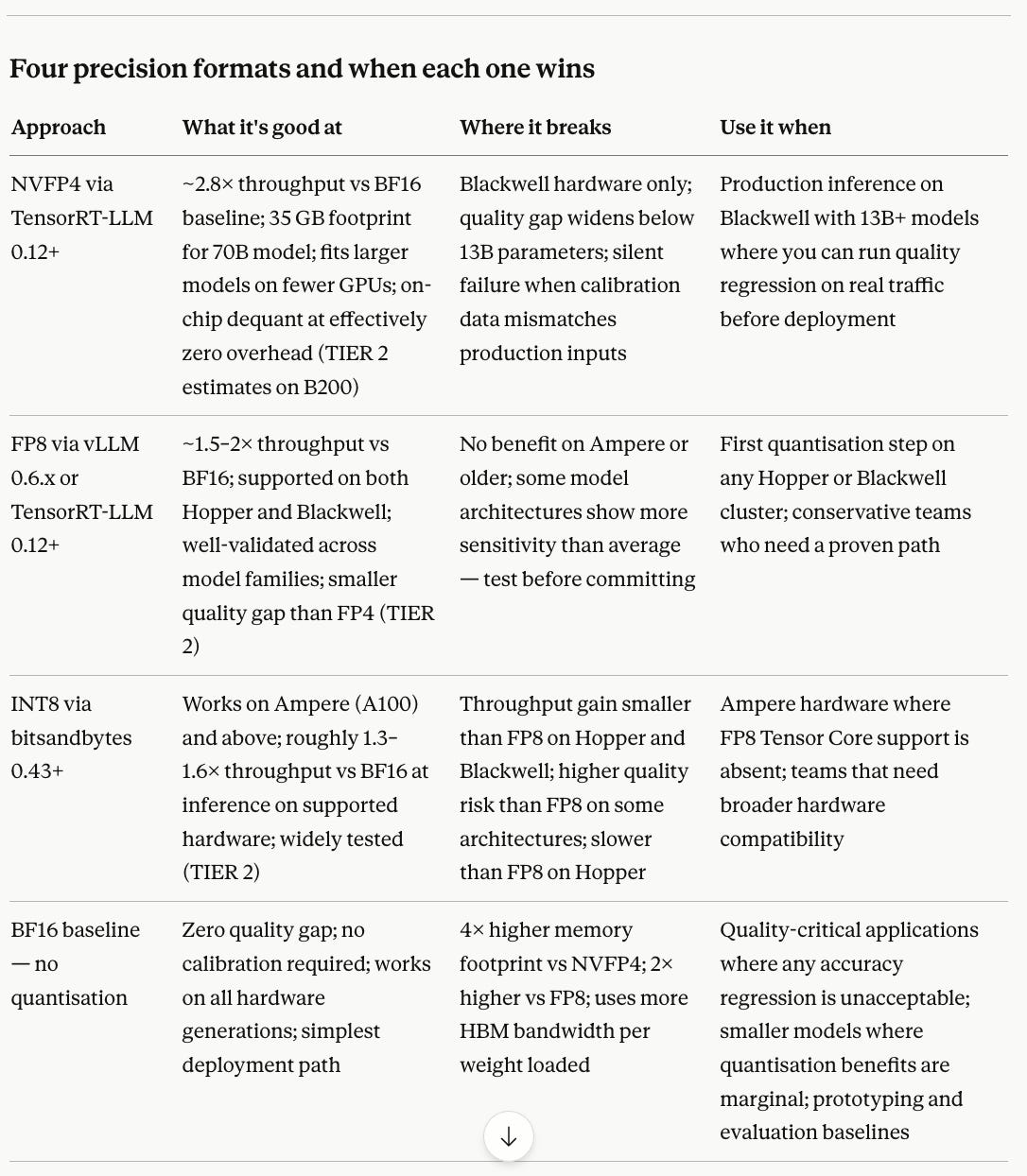
│ ├── YES → Use NVFP4 weight-only quantisation via TensorRT-LLM 0.12+.
│ │ Why: halves model footprint, doubles effective HBM throughput,
│ │ fits larger models on fewer GPUs.
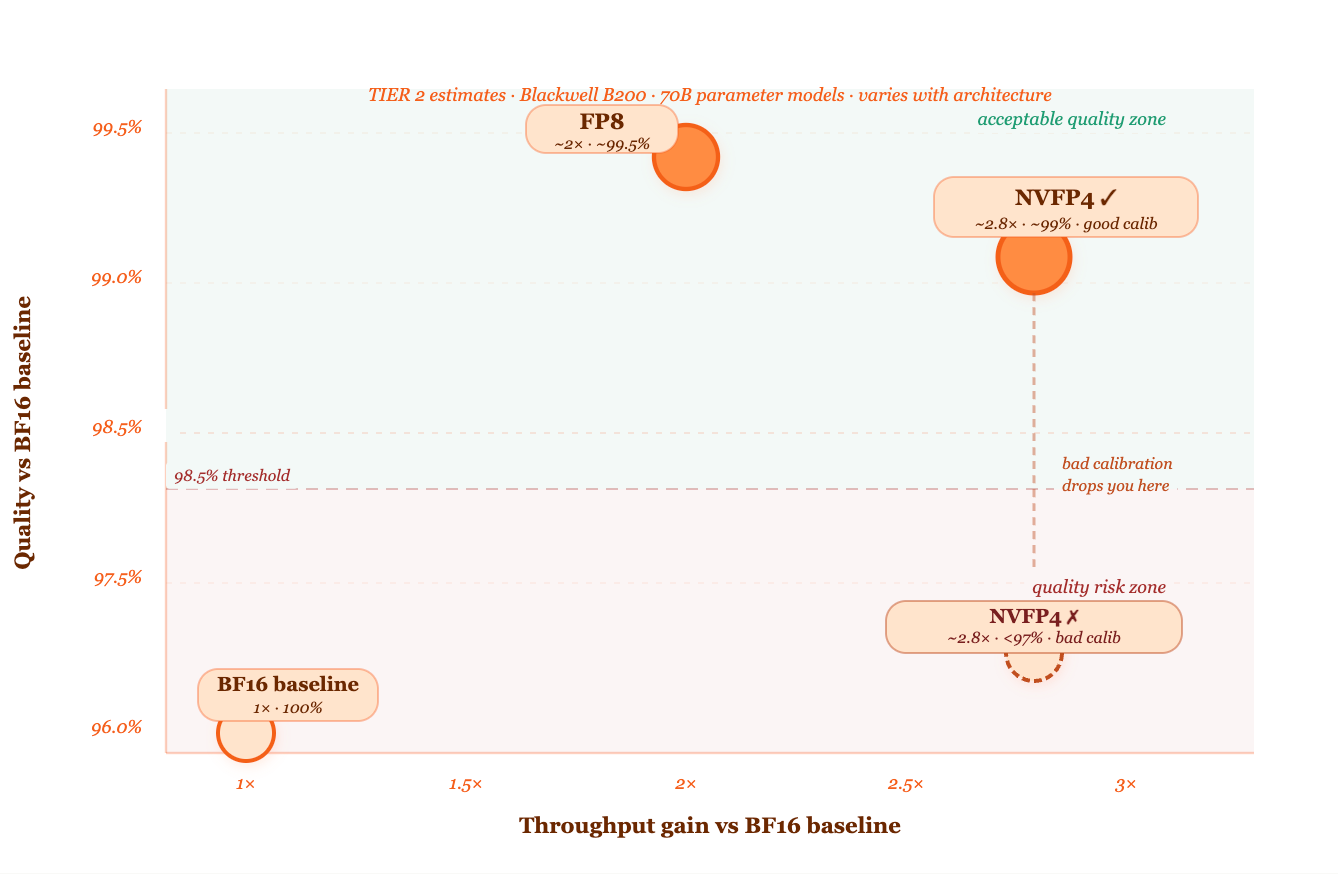
│ └── NO → Use FP8 (E4M3 or E5M2 depending on model sensitivity).
│ Why: FP8 is well-validated on Hopper and Blackwell, smaller
│ quality gap than FP4, still 2× memory reduction vs BF16.
└── NO → Do you have Hopper GPUs (H100 SXM5, H100 PCIe, H100 NVL)?
├── YES → Use FP8 via TensorRT-LLM 0.12+ or vLLM 0.6.x+ (fp8 backend).
│ Why: native FP8 Tensor Core support on Hopper, ~1.5–2×
│ throughput gain vs BF16 at similar quality. (TIER 2 range)
└── NO → Do you have Ampere (A100) or older?
├── YES → Use INT8 (via bitsandbytes or AutoGPTQ).
│ Why: best-supported quantisation path on Ampere,
│ widely validated, modest quality trade-off.
└── NO → Use BF16. Don't quantise.
Why: older hardware without quantised Tensor Core
support gains nothing from quantisation — the
dequantisation overhead erases any memory savings.
EDGE CASE: If fitting the model is the only goal,
try GPTQ 4-bit (AutoGPTQ) for capacity, accepting
a throughput penalty.Fewer bits per weight is inevitable — the question is just which generation ships it
Here’s the pattern that’s been running for a decade.
FP64 was the standard in scientific computing. FP32 became the AI training standard in 2012 when CUDA made GPU compute practical. FP16 became the inference standard around 2017. BF16 replaced FP16 for training around 2019 because of its wider exponent range. FP8 shipped on H100 in 2022. NVFP4 shipped on Blackwell in 2024.
Every step halved the bits. Every step came with an argument that accuracy would collapse. Every step, with proper calibration, produced smaller quality gaps than anyone expected. The pattern is consistent enough that you can predict the next step: FP2 or INT4 variants with even more aggressive calibration schemes will appear in the 2026–2028 hardware generation window.
The economic driver is permanent. Every bit you remove from a weight halves its storage cost and doubles how many weights you can move through a fixed-bandwidth memory link. With the memory wall being the primary inference bottleneck — as we covered in Issue #01 — anything that makes weights physically smaller directly attacks the most expensive constraint in the system. NVIDIA will keep pushing precision lower as long as accuracy holds. The model research community will keep developing calibration and quantisation methods that make accuracy hold at lower precisions.
Hugging Face, Meta, and several other labs have published quantisation research showing NVFP4 and aggressive INT4 methods preserving above 99% of BF16 accuracy on language modelling tasks for models above 7B parameters (TIER 2 — accuracy gap varies significantly with model architecture and quantisation implementation). Smaller models compress less cleanly — the 4-bit precision sweet spot currently sits at 13B parameters and above.
The throughput chart — where NVFP4 sits relative to other precisions
The myth that lower precision always means worse answers
The assumption is that cutting bits from a weight must degrade the model — that accuracy loss is proportional to precision loss, and 4 bits must produce a worse model than 8 bits, which must produce a worse model than 16 bits.
This is wrong for an important reason. Neural networks are not trying to represent arbitrary numbers. They learn weight distributions that cluster in predictable patterns. Large models — 13B parameters and above — have weight distributions that are particularly smooth and concentrated. The vast majority of weights in any given layer sit within a narrow range near zero. The extreme outliers are rare.
A 4-bit format calibrated against real production data doesn’t lose information uniformly. It loses information in the extreme ranges that your weights almost never occupy, and preserves precision in the ranges where they cluster. The information that actually encodes the model’s knowledge — the relative differences between weights in the dense cluster — is preserved to high accuracy.
The quality risk is real, but it’s specific. It comes from two sources: layers that have unusual weight distributions (embedding layers and the final output projection are common culprits), and inputs that fall outside the distribution your calibration set covered. Both are detectable with targeted evaluation.
The correct way to think about it: NVFP4 doesn’t reduce precision uniformly — it redirects precision from where your weights never live to where they actually cluster. The quality gap comes from calibration quality, not from the bit count itself.
[ FOR DECISION MAKERS ]
What this affects: The decision to upgrade to Blackwell-generation GPU hardware — and whether to run models in BF16, FP8, or NVFP4 once you do.
What it costs to get wrong: A team that deploys NVFP4 without a quality evaluation on real production queries can silently ship a degraded model. Users notice before the team does. The fix requires a full re-calibration and re-deployment cycle — typically days of engineering time.
One question to ask your engineering team: “When we quantise to a lower precision format, what evaluation do we run before the model goes live? Is it on real production queries or on generic benchmarks? If it’s only benchmarks, we might be missing quality regressions on our actual use case.”
Four precision formats and when each one wins
See it yourself — compare formats on your hardware
TOOL: vLLM 0.6.x (verify fp8 backend: vllm.readthedocs.io/en/latest/quantization)
For NVFP4: TensorRT-LLM 0.12+ on Blackwell hardware only
RUN: # FP8 baseline (works on Hopper H100 SXM5 or H100 PCIe)
python -m vllm.entrypoints.benchmark_throughput \
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
--quantization fp8 \
--num-prompts 200 --input-len 256 --output-len 128
# Repeat without --quantization flag for BF16 baseline comparison
CHANGE: --quantization flag (remove for BF16, set fp8 for FP8)
LOOK FOR: "Throughput: X.XX tokens/s" in the output for each run
EXPECTED RANGE: FP8 should show 1.4–1.9× throughput improvement vs BF16
on H100 SXM5 at batch sizes above 8 (TIER 2 — varies with
model architecture and batch composition)If you see less than 1.2× improvement from FP8 on H100 SXM5, check whether FP8 Tensor Core support is actually active — use
VLLM_TORCH_PROFILER_DIR=/tmp/profile python -m vllm... and look for FP8 kernel launches in the trace.
If this comes up in a system design interview
THE QUESTION:
Your team serves a 70B LLM on a cluster of Blackwell B200 GPUs. Your CTO
wants to cut inference cost by 50% within the next quarter without buying
more hardware or changing the model. Walk me through how you'd approach it.
WHAT A STRONG ANSWER COVERS:
- Identifies NVFP4 quantisation as the primary lever — halves model footprint,
roughly doubles effective HBM bandwidth utilisation on B200 hardware
- Names the calibration requirement — real production queries, not generic
benchmarks, and a quality regression eval before any deployment
- Acknowledges the risk: silent quality degradation if calibration is poor,
and states how they'd catch it — held-out production sample evaluation
WHAT MAKES IT A GREAT ANSWER:
A senior engineer separates the decision into two questions: "can we quantise?"
(hardware and model size check) and "should we quantise?" (quality risk
assessment on real traffic). Most mid-level engineers jump to implementation
without answering the second question.
FOLLOW-UP QUESTIONS:
Q2: "Your eval on held-out production queries shows 0.4% quality regression.
Your PM says that's acceptable. Your Head of AI says it isn't. How do
you resolve it and what do you ship?"
→ Good answer adds: run a targeted eval on the specific query types that
showed the largest regression — if it's concentrated in a specific domain
(e.g. code generation, maths), ship NVFP4 for everything else and keep
BF16 for the sensitive query type via a routing layer
Q3: "Three months later, you want to also apply NVFP4 to the KV cache, not
just the weights. What additional risks does that introduce?"
→ Good answer adds: KV cache quantisation affects the attention mechanism
during generation, not just loading — errors accumulate across long
sequences in ways that weight quantisation doesn't; recommend FP8 for
KV cache (more conservative) and NVFP4 for weights only; test on long-
context requests specifically, not just short ones
Q4: "The quality regression suddenly increases from 0.4% to 2.1% three
months into production. Nothing in the model changed. What happened
and how do you diagnose it?"
→ Good answer adds: the production input distribution shifted — users
started sending a different type of query that the calibration set
didn't cover; compare current production query distribution against
calibration dataset distribution; re-run calibration on a fresh sample
of recent production traffic and re-quantiseWhere the real technical depth is
→ FP8 Formats for Deep Learning — Micikevicius et al., NVIDIA, 2022
The foundational paper on 8-bit floating point for transformers.
Section 3 explains why exponent range matters more than mantissa bits
for transformer weights — directly applicable to understanding NVFP4.
→ NVIDIA Blackwell Architecture Technical Brief — NVIDIA, 2024
Primary source for NVFP4 Tensor Core specifications on B100/B200/GB200.
Read the memory subsystem section alongside the compute section.
→ LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
— Dettmers et al., NeurIPS 2022
Explains the outlier weight problem that makes naive quantisation fail —
the same problem NVFP4 calibration is designed to handle.
→ GPTQ: Accurate Post-Training Quantization for Generative Pre-trained
Transformers — Frantar et al., ICLR 2023
The calibration methodology used by most modern quantisation tools.
Understanding this makes NVFP4 calibration requirements make sense.
→ TensorRT-LLM quantisation documentation — NVIDIA developer docs, 2024
docs.nvidia.com/tensorrt-llm — the authoritative guide for NVFP4
deployment. More useful than any blog post on the topic.The bit count will keep dropping. The calibration problem won’t disappear.
Every precision format that shipped in the last decade was met with scepticism about accuracy. Every one delivered smaller quality gaps than the sceptics expected — at 13B parameters and above, with good calibration. The pattern will continue.
But calibration doesn’t get easier as precision drops. It gets harder. At 4 bits, the format has less room to absorb mismatch between the calibration distribution and the production distribution. Teams that invest in calibration infrastructure now — capturing, cleaning, and refreshing representative production queries on a regular schedule — will be able to adopt each new precision format cleanly as hardware ships it. Teams that treat calibration as a one-time setup task will discover that their quantised models quietly degrade as their users’ behaviour evolves.
The bit count is the hardware team’s problem. The calibration pipeline is yours.